锁C++实现
锁C++实现
读写锁C++实现
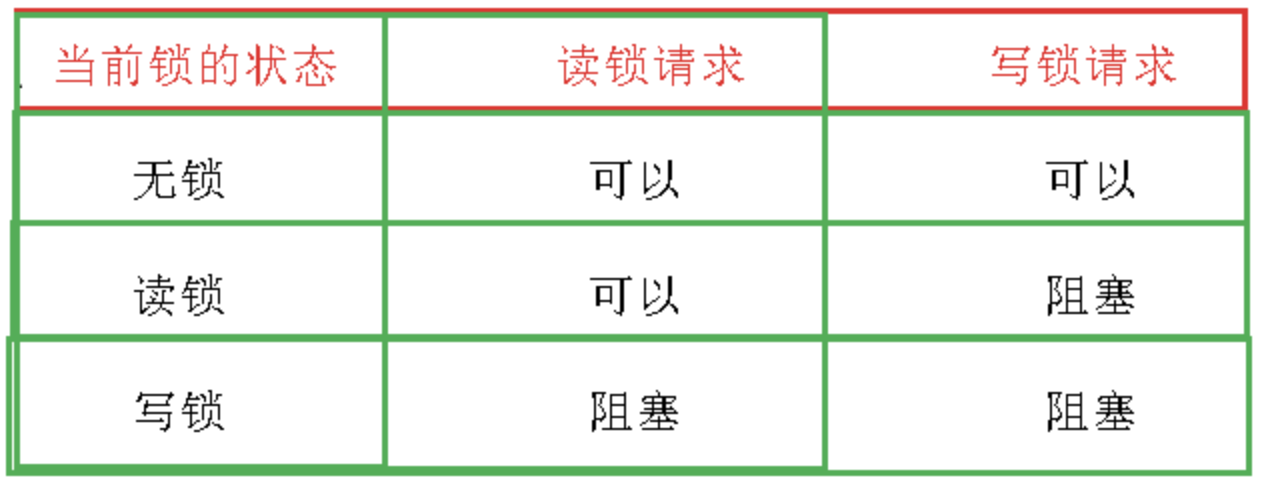
1 | class readWriteLock { |
从而实现上面描述的功能。
C++ 原子操作
原子操作即要么全部完成,要么没有执行的操作。
Intel x86指令集提供了指令前缀lock用于锁定前端串行总线(FSB),保证了指令执行时不会受到其他处理器的干扰。
使用lock指令前缀后,处理器间对内存的并发访问(读/写)被禁止,从而保证了指令的原子性
当一个CPU核执行一个线程去访问数据做操作的时候,它会向总线上发送一个LOCK信号,此时其他的线程想要去请求主内存的时候,就会被阻塞,这样该处理器核心就可以独享这个共享内存,而且释放锁后,会调用smp_mb invalide,使其他核心的缓存失效。
缓存一致性
当某核心对其缓存中的数据进行了操作之后,就通知其他核心放弃储存在它们内部的对应的缓存,或者从主内存中重新读取此数据。缓存一致性主要是通过MESI协议实现
C++ ATOMIC
在c++中,提供了atomic原子库,提供了对一些常用数据类型进行原子操作的接口
std::atomic_flag是一个原子的布尔类型,可支持两种原子操作: 1.test_and_set: 如果atomic_flag对象被设置,则返回true; 如果atomic_flag对象未被设置,则设置之,返回false 2.clear: 清除atomic_flag对象
自旋锁 自旋锁是一种busy-waiting的锁,即进程如果申请不到锁,会一直不断地循环检查锁(状态位)是否可用(会消耗cpu时间),直到获取到这个锁为止。 优点:不会使进程状态发生切换,即进程一直处于active状态,不会进入阻塞状态,获得锁后,不用进行上下文切换,执行速度快。 缺点:没有获得锁前,会一直消耗cpu时间。
可以用std::atomic_flag实现自旋锁
FUTEX
在Linux下,信号量和线程互斥锁的实现都是通过futex系统调用实现。 Futex 是一个提升效率的机制。在Unix系统中,传统的进程间同步机制都是通过对内核对象操作来完成的,这个内核对象在需要同步的进程中都是可见的,进程间的同步是通过系统调用在内核中完成。这种同步方式因为涉及用户态和内核态的切换,效率比较低。而且只要使用了传统的同步机制,进入临界区时即使没有其他的进程竞争也必须切换到内核态来检查内核同步对象的状态,这种不必要的切换显然带来了大量的浪费。 Futex就是为了解决这个问题而诞生的。Futex是一种用户态和内核态混合的同步机制,使用Futex同步机制,如果用于进程间同步,需要先创建一块共享内存,Futex变量就位于共享区。同时对Futex变量的操作必须是原子的,当进程试图进入临界区或者退出临界区的时候,首先检查共享内存中的Futex变量,如果没有其他的进程也申请使用临界区,则只修改Futex变量而不再执行系统调用。如果同时有其他进程在申请使用临界区,还是需要通过系统调用去执行等待或唤醒操作。这样通过用户态的Futex变量的控制,减少了进程在用户态和内核态之间切换的次数,从而减少了系统同步的开销。
mutex相关的函数并不是linux kernel实现的,而是glibc库实现的
锁最后也是由原子操作来实现的
来源:https://zhiqiang.org/coding/std-mutex-implement.html
在 C++里,标准库std::mutex只是一个pthread_mutex_t的封装
1 | class mutex { |
因此我们需要把眼光挪向pthread库的pthread_mutex_t以及相关函数。
pthread_mutex_t在 x86 下占据 32 个字节,内部布局如下:
1 | typedef union { |
其中上锁类型有下面几种取值:
- PTHREAD_MUTEX_TIMED_NP ,这是缺省值,也就是普通锁。
- PTHREAD_MUTEX_RECURSIVE_NP ,可重入锁,允许同一个线程对同一个锁成功获得多次,并通过多次 unlock 解锁。
- PTHREAD_MUTEX_ERRORCHECK_NP ,检错锁,如果同一个线程重复请求同一个锁,则返回 EDEADLK ,否则与 PTHREAD_MUTEX_TIMED_NP 类型相同。
- PTHREAD_MUTEX_ADAPTIVE_NP ,自适应锁,自旋锁与普通锁的混合。
下面我们看最关键的加锁函数pthread_mutex_lock,它的第一个参数是锁对象指针,第二个参数是上面的锁类型。如果是普通锁,它的实现就是:
1 | pthread_mutex_lock(pthread_mutex_t* mutex, int type) { |
下面我们看宏LLL_MUTEX_LOCK的实现:
1 | # define LLL_MUTEX_LOCK(mutex) \ |
其中PTHREAD_MUTEX_PSHARED用来区分线程锁还是进程锁。我们可以只关心线程锁,此时第二个参数就是LLL_PRIVATE=0。 而lll_lock的实现如下:
1 | #define lll_lock(futex, private) \ |
这一段是直接用汇编实现的。其核心指令是 cmpxchgl ,汇编级别的CAS( compare and swap )。如果 swap 不成功,则调用__lll_lock_wait_private让调度线程(进入操作系统的同优先级的任务队列末尾)。
从这里看,std::mutex的并没有加入自旋等待的实现。那么大家说的又是什么呢?其实是pthread_mutex_lock的PTHREAD_MUTEX_ADAPTIVE_NP锁方式。我们来看它的实现:
1 | if (type == PTHREAD_MUTEX_ADAPTIVE_NP) { |
这个实现已经和folly::MicroSpinLock基本没有两样了,甚至细节处理得更好一些,比如它每次的最大尝试次数是动态的,会根据之前的尝试次数调整。
但我还是更喜欢用folly::MicroSpinLock,因为内存结构更简单(只占一个字节,而pthread_mutex_t需要 32 个字节!), API 相比起 C 风格的 pthread 也更顺手一些。